Word embeddings attempt to represent the meaning of words using lower-dimensional real-valued vectors such that words that have similar meaning are embedded close to each other in the embedding space. Counting-based approaches that create word embeddings in a top-down fashion have been overtaken by prediction-based methods, which (randomly) initialise the embeddings and subsequently update them such that the words in their co-occurrence contexts can be accurately predicted. Arguably word2vec¹ is the most popular suite of algorithms for learning word embeddings but the history of neural embeddings dates back to the work by Bengio (2008).
As described above, word embeddings are learnt without any human supervision, beyond providing texts written by humans (ideally native speakers). Therefore, this process can be seen as unsupervised (or a better term would be self-supervised) learning. A remarkable property that was reported by Mikolov et al (2013) is that the word embeddings learnt in this manner encodes analogical knowledge such as the vector formed by king-man+woman is closest (in the Euclidean distance) to the embedding of queen. Now, before you get too excited about this, it is worth mentioning that much of this seemingly remarkable analogy capturing property can be attributable to the ability of word embeddings to learn nearest neighbours and not necessarily something to be too excited about.
The worrying bit is yet to come …
In their pioneering work investigating word embeddings, Bolukbasi et al (2016) showed that word embeddings encode gender biases as well! For example, they showed that man-programmer+woman becomes closer to homemaker. They proposed a method (hard debiasing) for correcting this issue by projecting word embeddings into a space orthogonal to the gender direction, defined using a set of gender-defining word-pairs such as (she, he), (woman, man), (female, male) etc. Later work on gender debiasing has proposed adversarial methods to remove bias in pre-trained embeddings as well as methods for learning debiased embeddings from scratch.
Despite these efforts, it was later found that adversarial methods are inadequate to remove gender-biases completely and even after applying these debiasing methods we can still discover gender stereotypes by clustering the words. Moreover, it has also been reported that much of the biases reported in prior work are sensational party tricks and an artefact of the analogy prediction method rather than a problem in the embeddings themselves. Nevertheless, word embeddings do capture biases and it is not limited to gender but extend to racial and religious biases as well.
So something has to be done …
Removing biases from pre-trained word embeddings can be seen as an information removal operation. After all we are removing something that was already learnt by the word embedding learning algorithm and embedded into the vectors. However, if we remove too much, then we loose the accuracy of the embeddings and will result in lower performance in tasks that use the debiased embeddings. So we must be careful not to remove too much information from the embeddings during the debiasing process. More precisely, we must remove the stereotypical gender biases while preserving useful gender-related information as much as possible.
Gender-preserving word embeddings …
In our long paper to be presented at the Annual Conference of the Association for Computational Linguistics (ACL-19) in July 2019, we propose a method that preserves gender-related information, while removing stereotypical information from pre-trained word embeddings. In our method we balance four different objectives:
- For words that have a female association, we preserve their feminine properties.
- For words that have a male association, we preserve their masculine properties.
- For words that are gender-neutral, we preserve their gender-neutrality.
- For stereotypical words (words that are incorrectly associated with a gender when they should have not been), we remove their gender associations.
Each of the above-mentioned criteria is expressed as a reconstruction loss and their linearly-weighted sum is then minimised to learn a debiasing mapping. In our experiments, we debias pre-trained GloVe embeddings and show that the proposed method (GP GloVe) accurately removes gender-biases from the word embeddings, while preserving useful information for semantic similarity and analogy prediction tasks. To appreciate the effect on a visual manner consider the for gender-neutral, gender-oriented and stereotypical words shown below. We have measured the similarity between each word and the gender direction computed as the vector corresponding to she-he.
|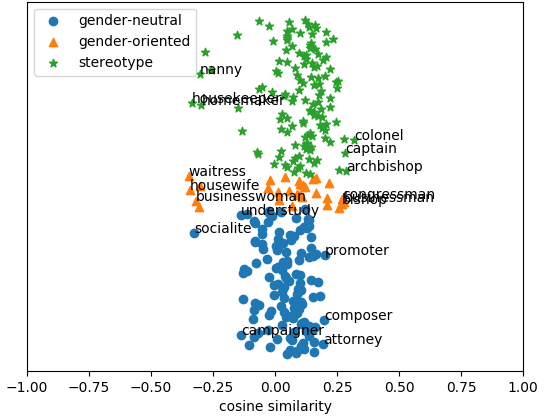 |
| Original Glove Embeddings |
|
| Original Glove Embeddings |
|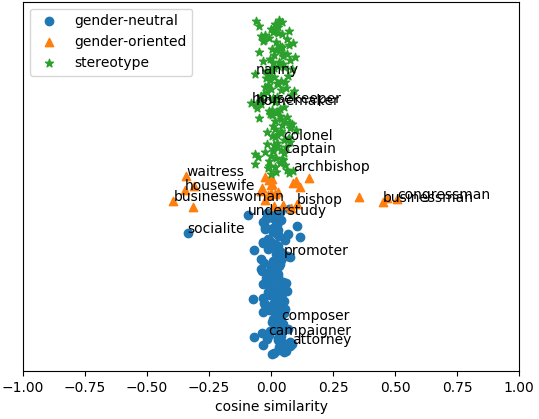 |
| Debiased embeddings using hard-debias method |
|
| Debiased embeddings using hard-debias method |
|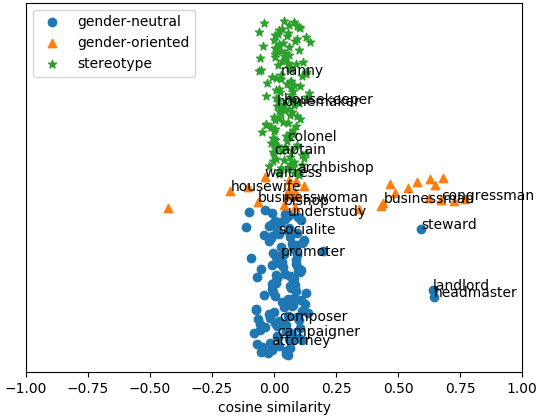 |
| Debiased embeddings using Gender Neutral debiasing method |
|
| Debiased embeddings using Gender Neutral debiasing method |
|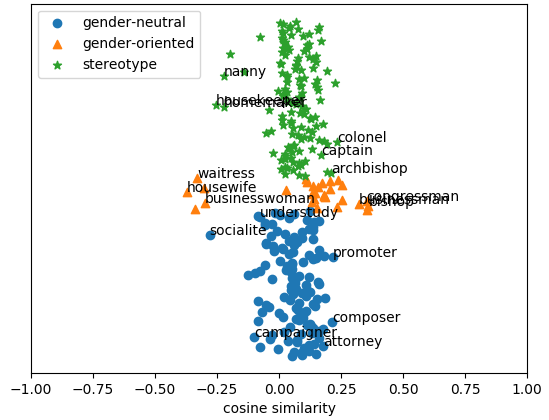 |
| Debiased embeddings using the proposed Gender Preserving debiasing method |
|
| Debiased embeddings using the proposed Gender Preserving debiasing method |
We see that the proposed method remove gender information mainly from the stereotypical words, whereas prior methods do so for all types of words, including gender-definitional non-stereotypical words as well. For further details refer to the paper.
Notes
- word2vec is a tool for embedding words and implements two algorithms for this purpose: continuous bag-of-words (CBOW) model and skip-gram with negative sampling (SGNS). Despite the fact that these are related but different methods, it is worrying to see that word2vec is used as if it is an algorithm itself and not indicating which embedding learning algorithm is actually used.